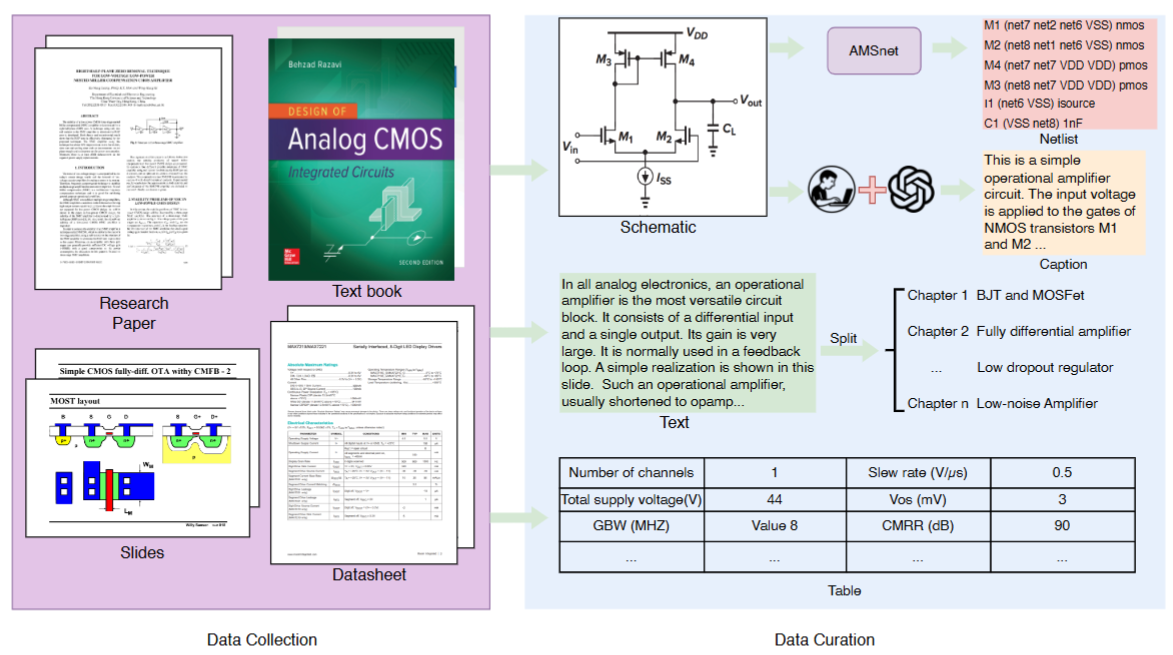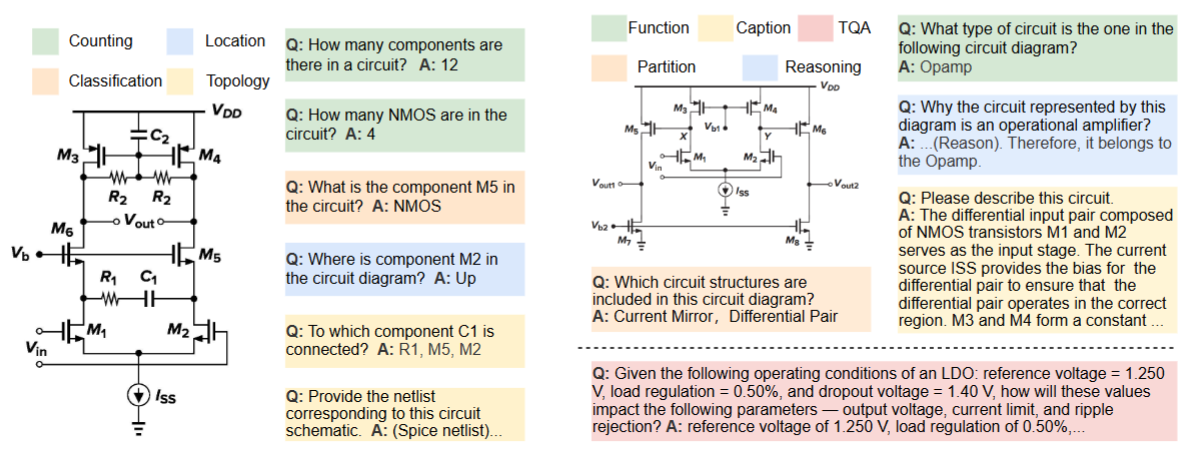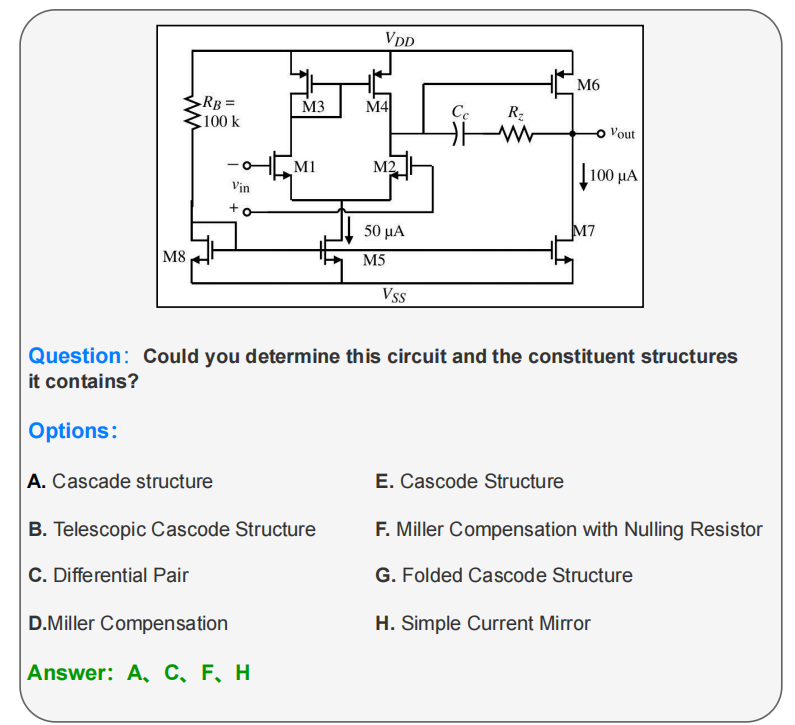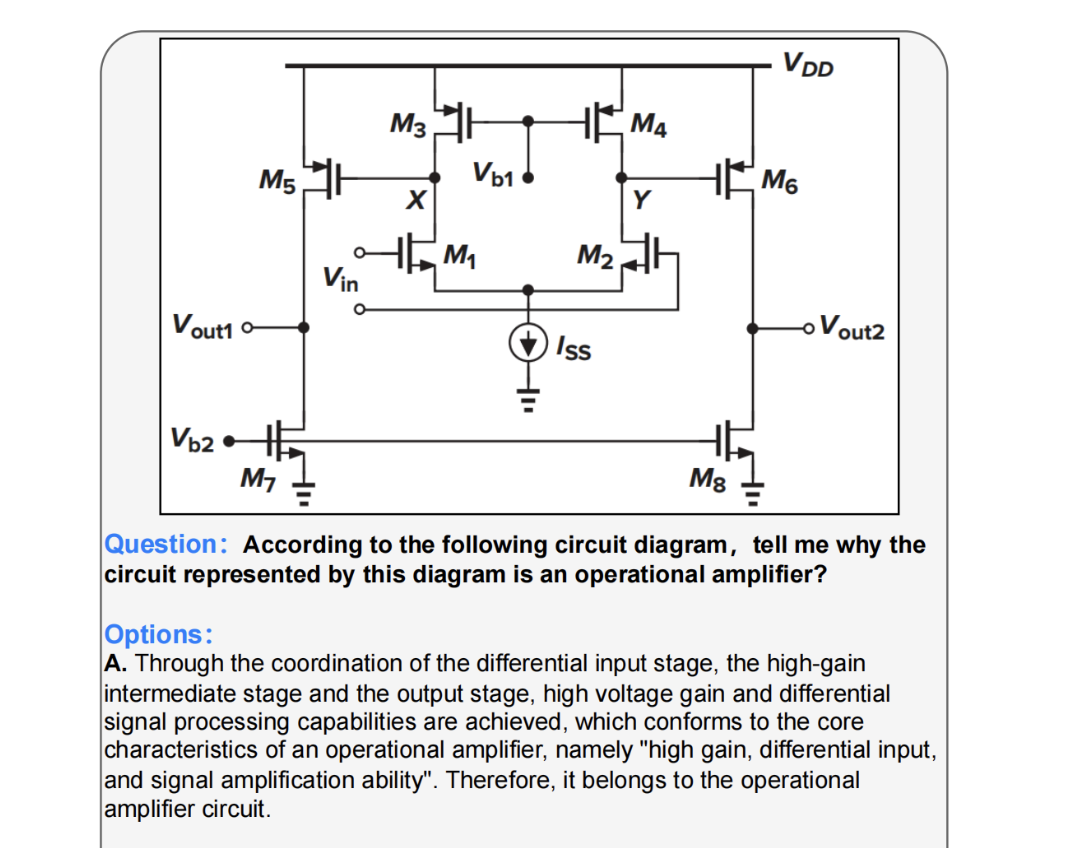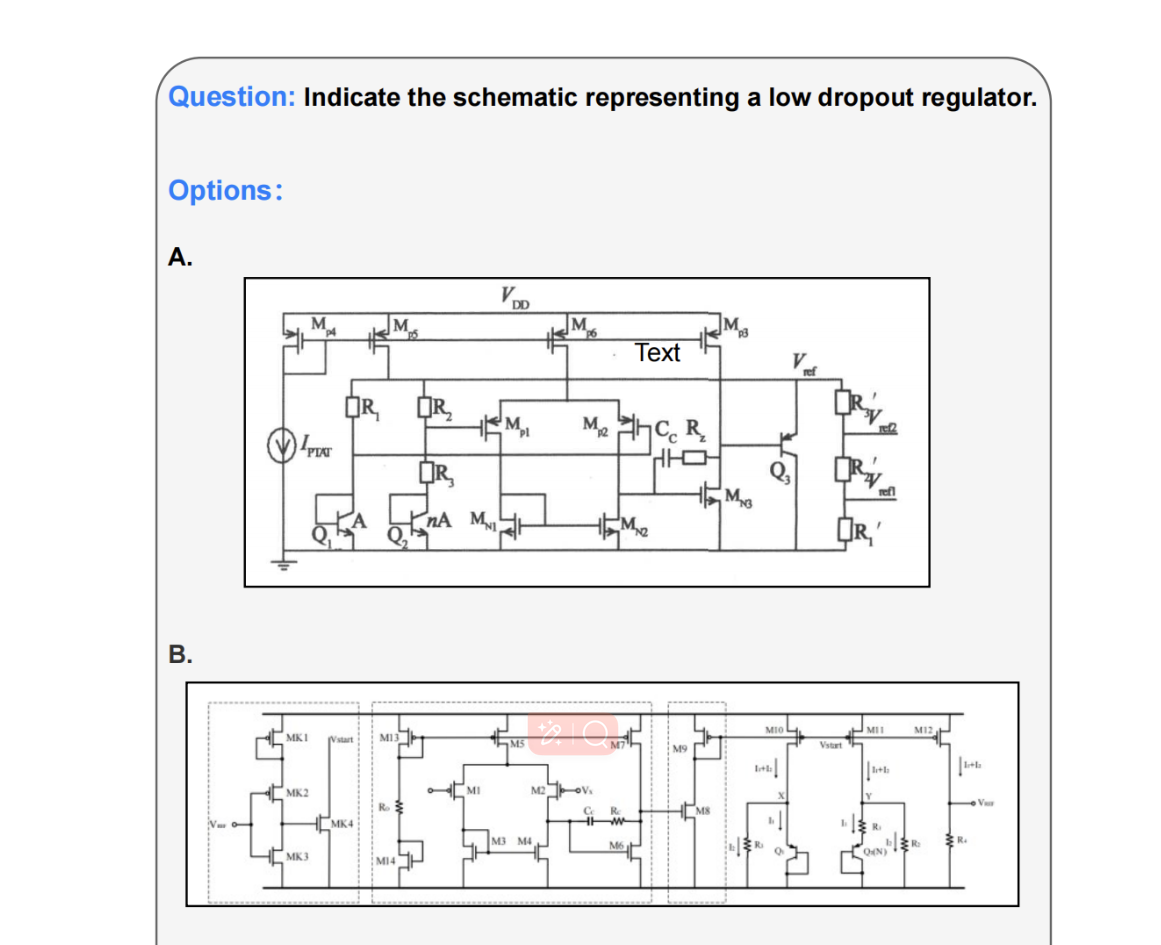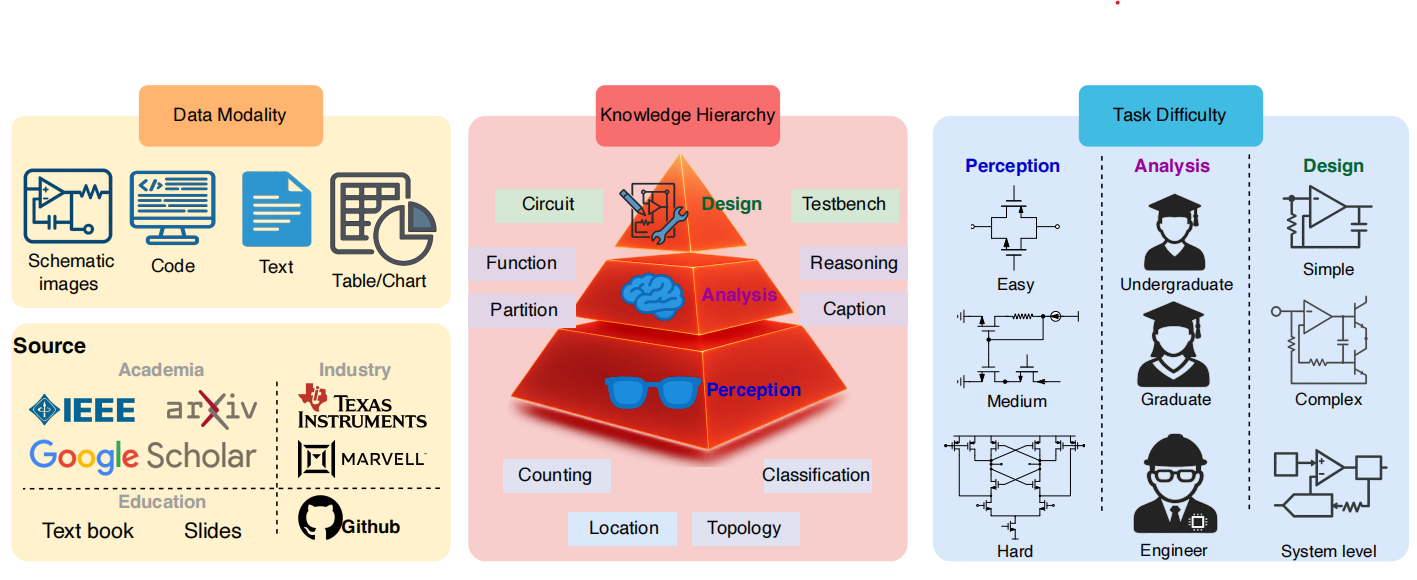
Analog/Mixed-Signal (AMS) circuits play a critical role in the integrated circuit (IC) industry. However, automating AMS circuit design has remained a longstanding challenge due to its difficulty and complexity. Recent advances in Multi-modal Large Language Models (MLLMs) offer promising potential for supporting AMS circuit analysis and design. However, current research typically evaluates MLLMs on isolated tasks within the domain, lacking a comprehensive benchmark that systematically assesses model capabilities across diverse AMS-related challenges.
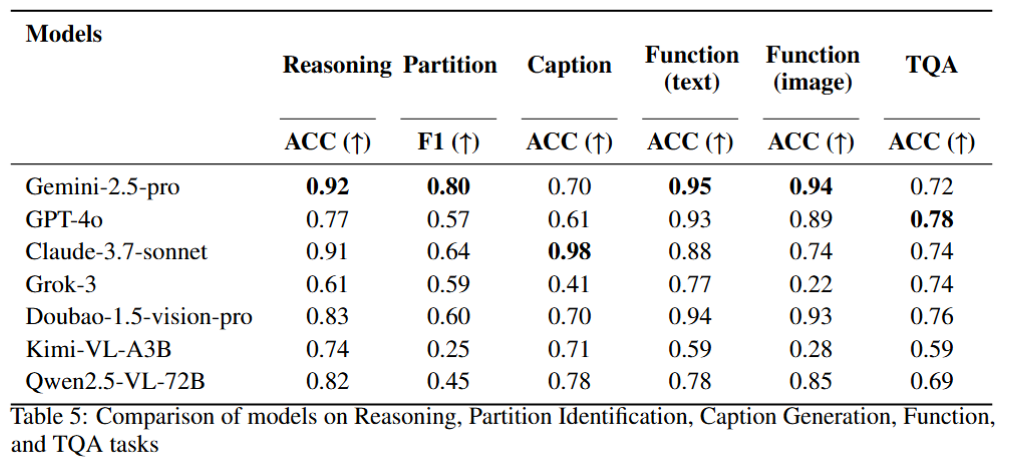
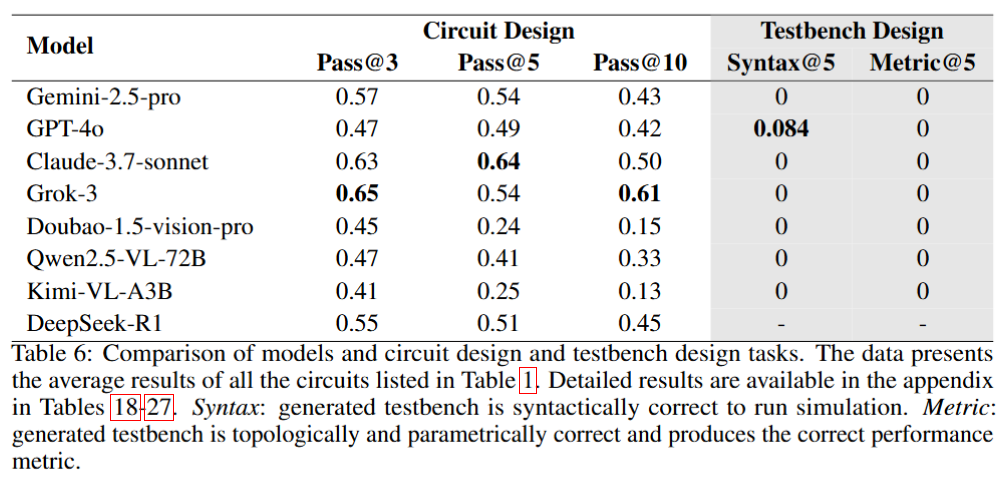
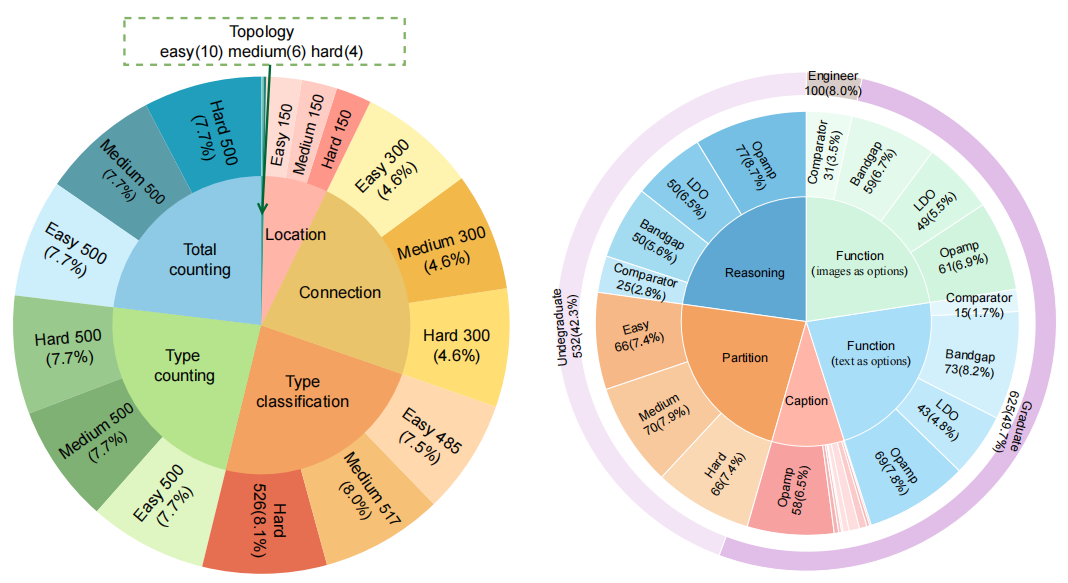
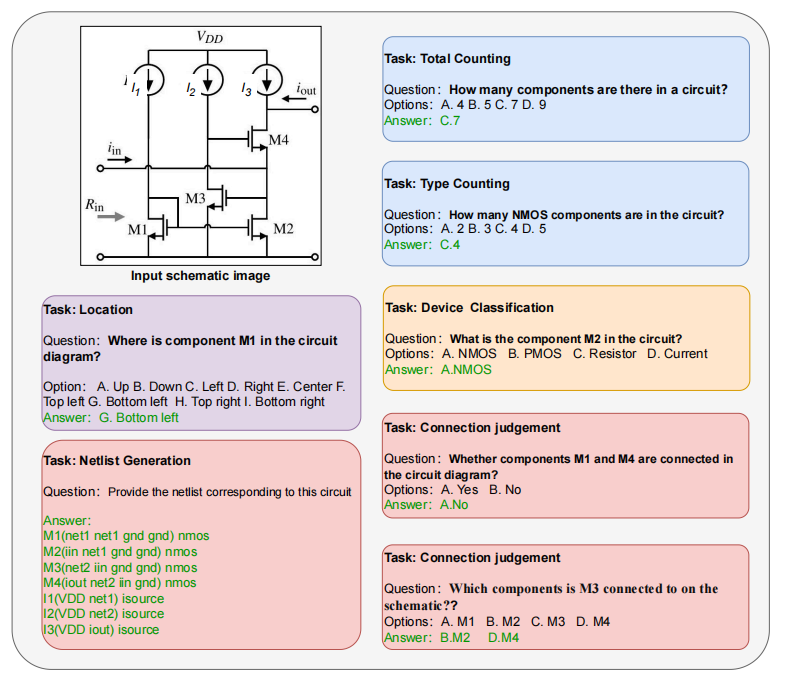
To address this gap, we introduce AMSbench, a benchmark suite designed to evaluate MLLM performance across critical tasks including circuit schematic perception, circuit analysis, and circuit design. AMSbench comprises approximately 8000 test questions spanning multiple difficulty levels and assesses eight prominent models, encompassing both open-source and proprietary solutions such as Qwen 2.5-VL and Gemini 2.5 Pro.
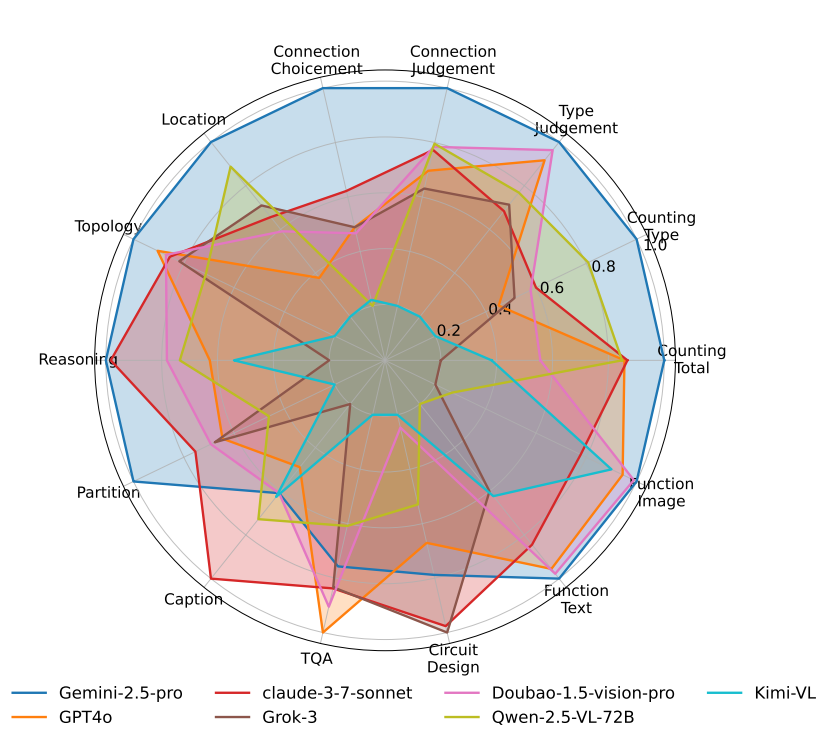
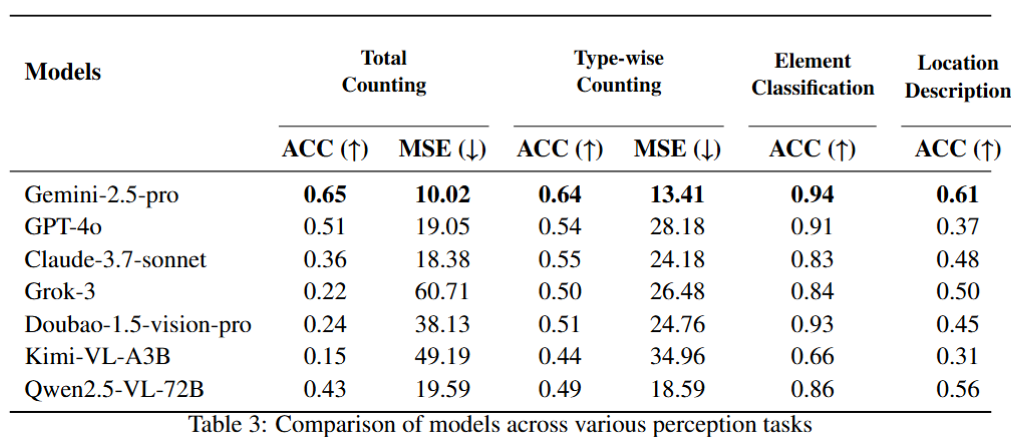
Our evaluation highlights significant limitations in current MLLMs, particularly in complex multi-modal reasoning and sophisticated circuit design tasks. These results underscore the necessity of advancing MLLMs’ understanding and effective application of circuit-specific knowledge, thereby narrowing the existing performance gap relative to human expertise and moving toward fully automated AMS circuit design workflows. Our data is released at this URL.